HashMap面试相关[数据结构、扩容机制、算法优化]
数据结构
JDK1.7及之前底层是数组和链表
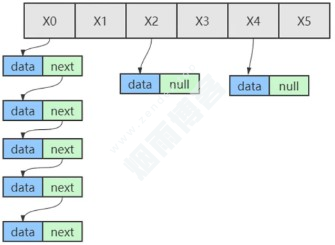
JDK1.8及之后底层是数组、链表、红黑树
HashMap在元素比较少的时候,结构是:数组+链表
hash算法和寻址算法是如何优化的?
基于二进制位运算的优化。
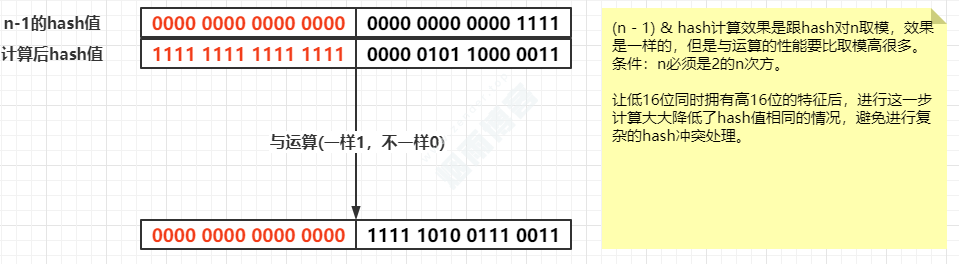
先通过hashCode()获得hash,再把这个hash去二进制位运算,向右移16位。得到一个新hash。
通过新hash和旧hash进行异或运算,得出的hash,它低16位同时拥有高16位的特性。这样尽量避免了一些hash冲突。

寻址算法优化
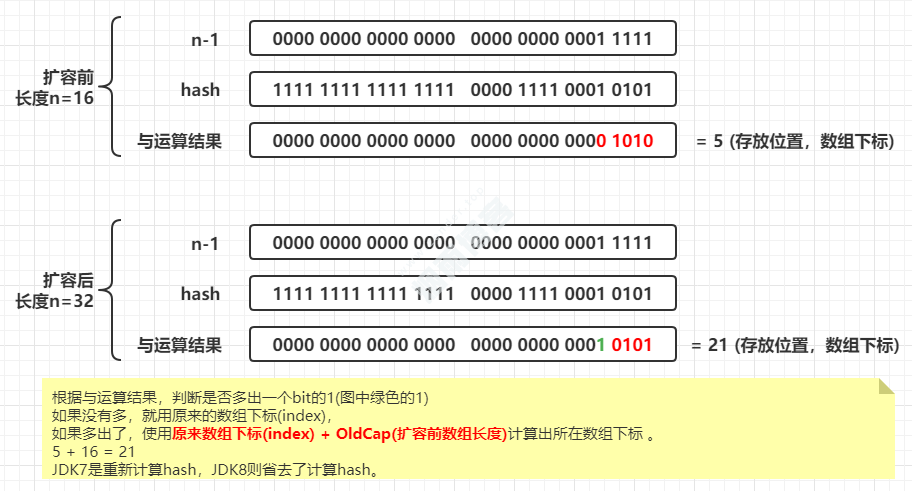
JDK8不在对数组长度取模,而是通过(n-1) & hash,n是数组长度。
(n-1) & hash 计算效果是和取模是一样的,但性能更高,但是有个条件n必须是2的n次方。
如何解决hash碰撞?
hash碰撞也就是说:两个key/多个key,他们计算出来的hash值 ,与n-1,与运算后,发现定位出来的数组位置是一样的。
这个时候就会在数组这个位置挂一个链表来存放多个元素。
链表如果长了,会导致寻址过慢。JDK8进行了优化,当链表长度大于8时,HashMap链表会转换为红黑树(且满足一个条件:数组长度必须大于等于64),否则只是进行扩容。
如何进行扩容的?
扩容机制:会判断当前容器的元素个数,如果大于等于阈(yu)值(当前数组的长度乘以加载因子[0.75]的值),就要自动扩容[2倍]。
比如:数组长度16,如果数组有12个元素[16*0.75=12]时,就会扩容。
JDK8对扩容进行了优化,省去了从新计算hash。并且扩容时,如果是红黑树,还会对红黑树进行修剪,比如会对节点进行分类、元素达不到阈值,会还原成链表。
与Hashtable的不同?
Hashtable线程安全,HashMap非线程安全。
Hashtable的key不能是null,HashMap可以,不过避免使用null作为key。
版权声明
非特殊说明,本文由Zender原创或收集发布,欢迎转载。
上一篇:7、Spring源码-循环依赖 下一篇:Java基础面试题
相关文章



作者文章
- MyBatisCodeHelper-Pro3.3.6+2321破解 2年前 (2024-10-17)
- 网站迁移公告 2年前 (2024-10-10)
- Java项目防止SQL注入4总方式 3年前 (2023-09-06)
- JAVA开发小技巧--读取文件魔数来识别文件类型 3年前 (2023-08-24)
- 分类树菜单优化 3年前 (2023-08-22)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。