通过idea64.exe.vmoptions了解一些JVM参数
下面是个人使用的Idea2020.1.2的配置idea64.exe.vmoptions文件内容
-server -Xms512m -Xmx1024m -Xmn393m -Xverify:none -ea -XX:+AlwaysPreTouch -XX:MaxGCPauseMillis=100 -XX:+UseConcMarkSweepGC -XX:ParallelGCThreads=4 -XX:+CMSParallelRemarkEnabled -XX:ConcGCThreads=4 -XX:CICompilerCount=4 -XX:ReservedCodeCacheSize=240m -XX:+TieredCompilation -XX:+UseCompressedOops -XX:SoftRefLRUPolicyMSPerMB=50 -XX:MaxTenuringThreshold=10 -XX:-OmitStackTraceInFastThrow -Dsun.io.useCanonCaches=false -Dsun.io.useCanonPrefixCache=false # 设置禁用IPv6 -Djava.net.preferIPv4Stack=true -Djdk.http.auth.tunneling.disabledSchemes="" -Djdk.attach.allowAttachSelf -Dkotlinx.coroutines.debug=on -Djdk.module.illegalAccess.silent=true
一、-server
二、-Xmx1024m -Xms512m -Xmn393m -Xverify:none
三、-XX:+AlwaysPreTouch
-
第1次YGC(年轻带GC)之前Eden区分配对象的速度较慢;
-
YGC(年轻带GC)的时候,Young区的对象要晋升到Old区的时候,这个时候需要操作系统真正分配内存,这样就会加大YGC(年轻带GC)的停顿时间。
[root@node2 afei]# date; java -Xmx16G -Xms16G -XX:+AlwaysPreTouch Test; dateTue Jan 15 14:31:59 CST 2019 Hello World!Tue Jan 15 14:32:35 CST 2019[root@node2 afei]# date; java -Xmx16G -Xms16G -XX:-AlwaysPreTouch Test; dateTue Jan 15 14:33:55 CST 2019 Hello World!Tue Jan 15 14:33:55 CST 2019[root@node2 afei]# date; java -Xmx8G -Xms8G -XX:+AlwaysPreTouch Test; dateTue Jan 15 14:32:53 CST 2019 Hello World!Tue Jan 15 14:33:13 CST 2019[root@node2 afei]# date; java -Xmx8G -Xms8G -XX:-AlwaysPreTouch Test; dateTue Jan 15 14:36:48 CST 2019 Hello World!Tue Jan 15 14:36:48 CST 2019
3.1、慢的原因
3.2、根本原因
四、-XX:MaxGCPauseMillis=100
五、-XX:+UseConcMarkSweepGC -XX:ParallelGCThreads=4 -XX:+CMSParallelRemarkEnabled
六、-XX:ConcGCThreads=4
CMS默认启动的并发线程数是(ParallelGCThreads+3)/4。
当有4个并行线程时,有1个并发线程,当有5~8个并行线程时,有2个并发线程。
七、-XX:ReservedCodeCacheSize=240m
八、-XX:+TieredCompilation
8.1、HotSpot的分层编译模式
8.2、分层编译
Java 7 引入了分层编译(对应参数 -XX:+TieredCompilation)的概念,综合了 C1 的启动性能优势和 C2 的峰值性能优势。
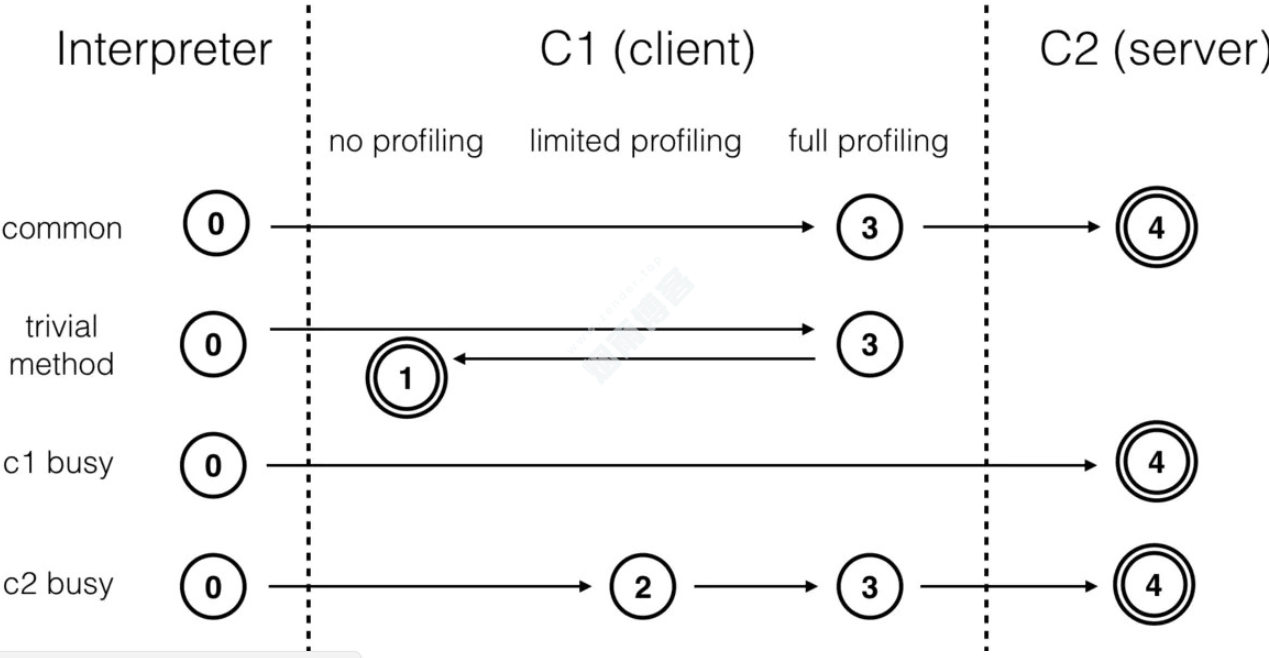
分层编译将 Java 虚拟机的执行状态分为了五个层次。为了方便阐述,我用“C1 代码”来指代由 C1 生成的机器码,“C2 代码”来指代由 C2 生成的机器码。五个层级分别是:
-
解释执行;
-
执行不带 profiling 的 C1 代码;;
-
执行仅带方法调用次数以及循环回边执行次数 profiling 的 C1 代码;
-
执行带所有 profiling 的 C1 代码;
-
执行 C2 代码;
其中 1 层的性能比 2 层的稍微高一些,而 2 层的性能又比 3 层高出 30%。这是因为 profiling 越多,其额外的性能开销越大。
九、-XX:+UseCompressedOops
十、-XX:SoftRefLRUPolicyMSPerMB=50
十一、-XX:MaxTenuringThreshold=10
设置在年轻代(Young Generation)中对象存活次数(经过Minor GC的次数)后仍然存活,就会晋升到老年代(Old Generation)。
十二、-XX:CICompilerCount=4
设置最大并行编译数为4。
十三、-XX:-OmitStackTraceInFastThrow
十四、-Dkotlinx.coroutines.debug=on
版权声明
非特殊说明,本文由Zender原创或收集发布,欢迎转载。

作者文章
- MyBatisCodeHelper-Pro3.3.6+2321破解 2年前 (2024-10-17)
- 网站迁移公告 2年前 (2024-10-10)
- Java项目防止SQL注入4总方式 3年前 (2023-09-06)
- JAVA开发小技巧--读取文件魔数来识别文件类型 3年前 (2023-08-24)
- 分类树菜单优化 3年前 (2023-08-22)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。