数据库慢查询的12个原因
1. SQL没加索引
where 的条件列,建立索引,尽量避免全表扫描。
正例:

2. SQL 索引不生效
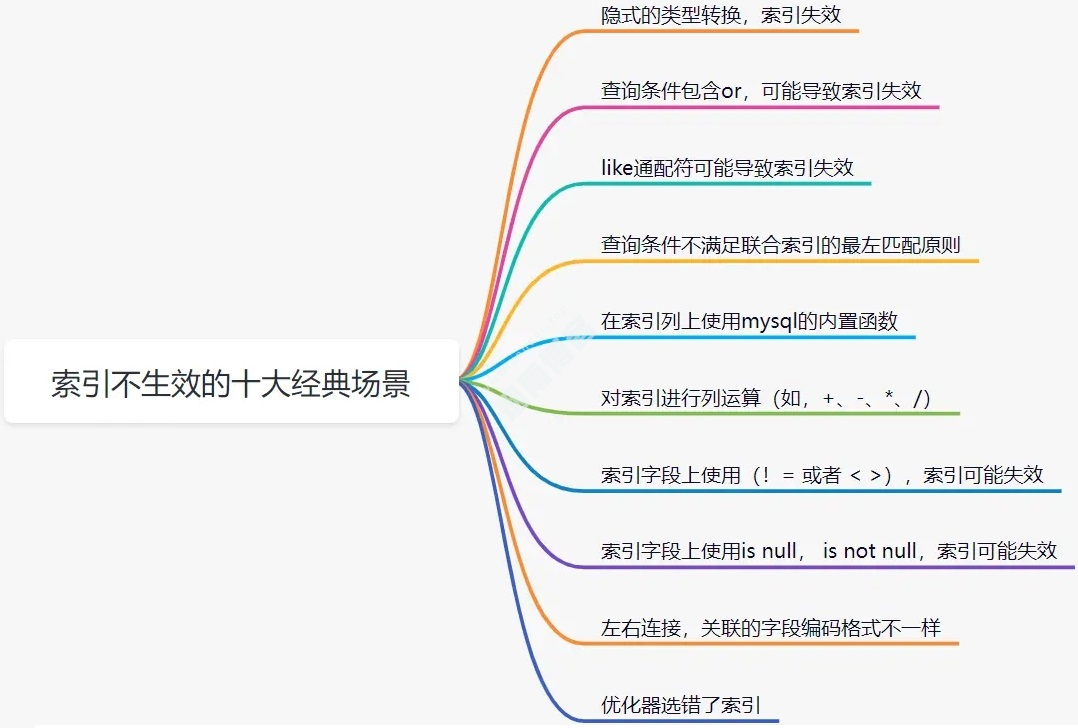
2.1 隐式的类型转换,索引失效
CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, userId varchar(32) NOT NULL, age varchar(16) NOT NULL, name varchar(255) NOT NULL, PRIMARY KEY (id), KEY idx_userid (userId) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
userId 字段为字串类型,是B+树的普通索引,如果查询条件传了一个数字过去,会导致索引失效。如下:

如果给数字加上'',也就是说,传的是一个字符串呢,当然是走索引,如下图:

2.2 查询条件包含or,可能导致索引失效
其中 userId 加了索引,但是 age 没有加索引的。我们使用了 or,以下SQL是不走索引的,如下:
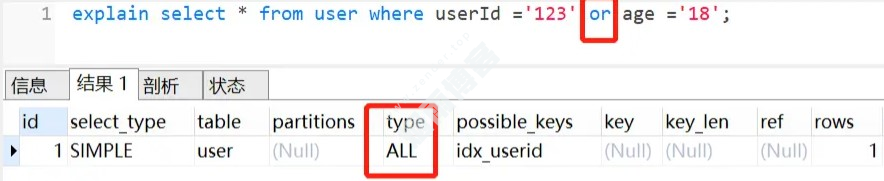
对于 or +没有索引的 age 这种情况,假设它走了 userId 的索引,但是走到 age 查询条件时,它还得全表扫描,也就是需要三步过程:全表扫描+索引扫描+合并
如果它一开始就走全表扫描,直接一遍扫描就完事。Mysql优化器出于效率与成本考虑,遇到 or 条件,让索引失效,看起来也合情合理嘛。
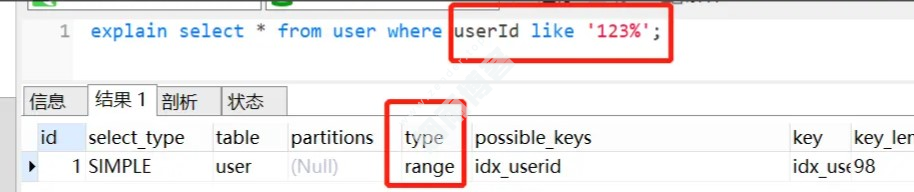
or 条件的列都加了索引,索引可能会走也可能不走(看数据量的大小,太少也有可能走全表扫描)。2.3. like通配符可能导致索引失效
并不是用了 like 通配符,索引一定会失效,而是like查询是以%开头,才会导致索引失效。
like查询以%开头,索引失效

把%放后面,发现索引还是正常走的,如下:
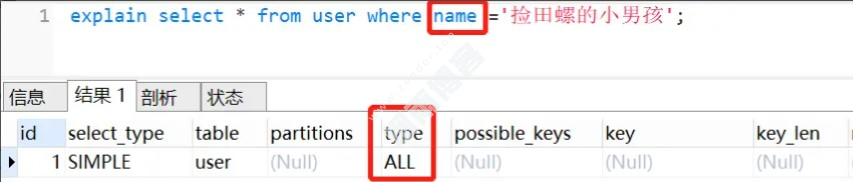
2.4 查询条件不满足联合索引的最左匹配原则
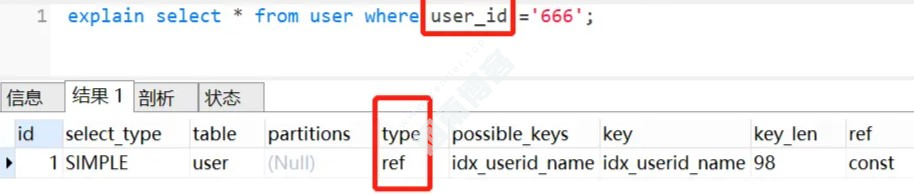
(a,b,c)的联合索引,相当于建立了(a)、(a,b)、(a,b,c)三个索引。CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, user_id varchar(32) NOT NULL, age varchar(16) NOT NULL, name varchar(255) NOT NULL, PRIMARY KEY (id), KEY idx_userid_name (user_id,name) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
有一个联合索引 idx_userid_name,我们执行这个SQL,查询条件是 name,索引是无效:
在联合索引中,查询条件满足最左匹配原则时,索引才正常生效。
2.5 在索引列上使用mysql的内置函数
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` varchar(32) NOT NULL, `login_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `idx_userId` (`userId`) USING BTREE, KEY `idx_login_time` (`login_Time`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
虽然login_time加了索引,但是因为使用了mysql的内置函数Date_ADD(),索引直接GG,如图:

一般这种情况怎么优化呢?可以把内置函数的逻辑转移到右边,如下:

2.6 对索引进行列运算(如,+、-、*、/),索引不生效
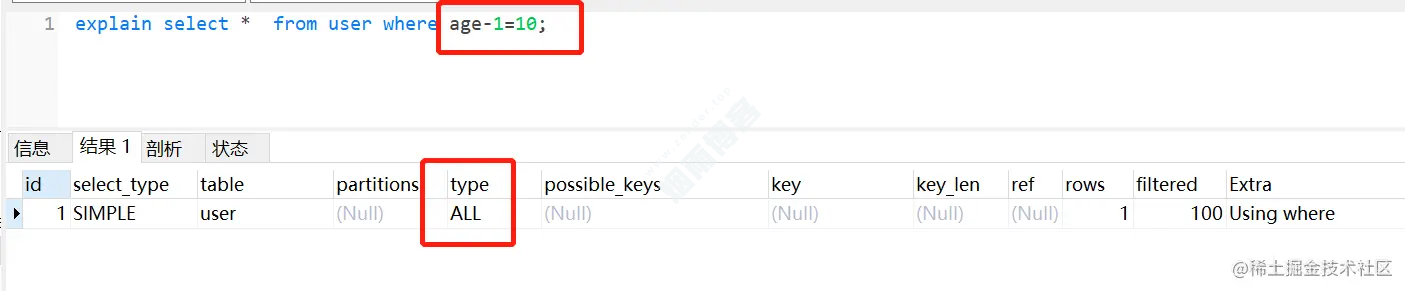
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` varchar(32) NOT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
虽然age加了索引,但是因为它进行运算,索引直接迷路了。。。 如图:
所以不可以对索引列进行运算,可以在代码处理好,再传参进去。
2.7 索引字段上使用(!= 或者 < >),索引可能失效
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` int(11) NOT NULL, `age` int(11) DEFAULT NULL, `name` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
虽然age加了索引,但是使用了!= 或者< >,not in这些时,索引如同虚设。如下:


其实这个也是跟 mySql优化器 有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行的哈,它觉得不划算,不如直接不走索引。平时我们用!= 或者< >,not in的时候,留点心眼哈。
2.8 索引字段上使用is null, is not null,索引可能失效
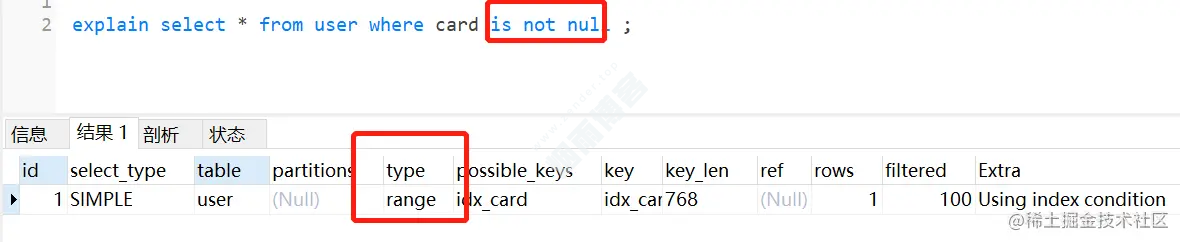
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `card` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE, KEY `idx_card` (`card`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
单个 name 字段加上索引,并查询 name 为非空的语句,其实会走索引的,如下:

单个card字段加上索引,并查询name为非空的语句,其实会走索引的,如下:
但是它两用or连接起来,索引就失效了,如下:
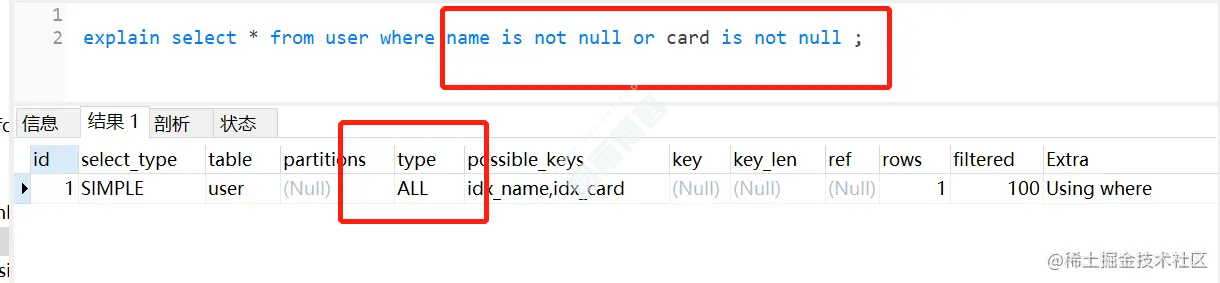
type=range,要注意一下哈,因为这个可能因为数据量问题,导致索引没无效。2.9 左右连接,关联的字段编码格式不一样
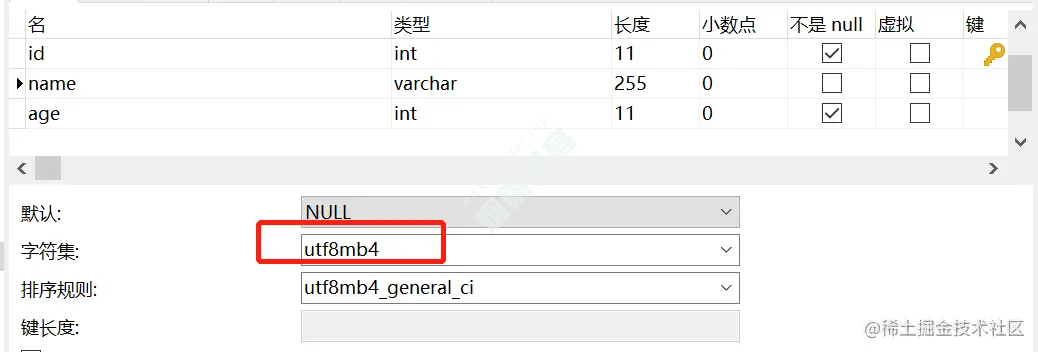
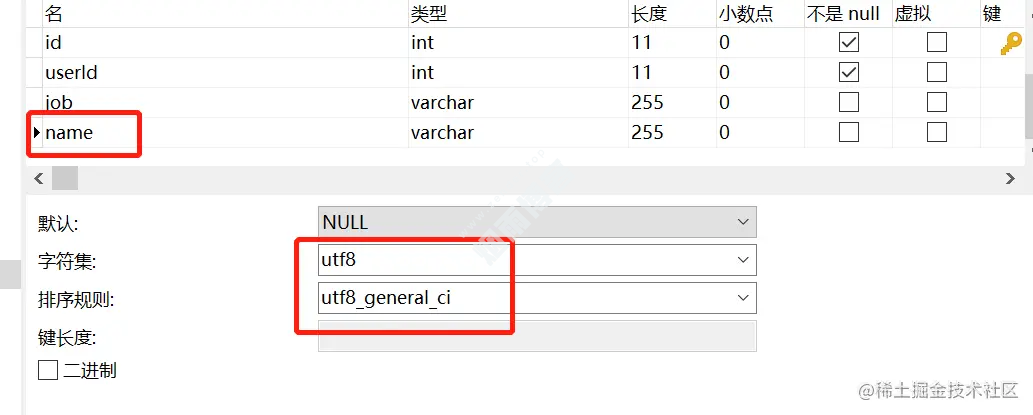
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL, `age` int(11) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8; CREATE TABLE `user_job` ( `id` int(11) NOT NULL, `userId` int(11) NOT NULL, `job` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
user表的name字段编码是utf8mb4,而user_job表的name字段编码为utf8。
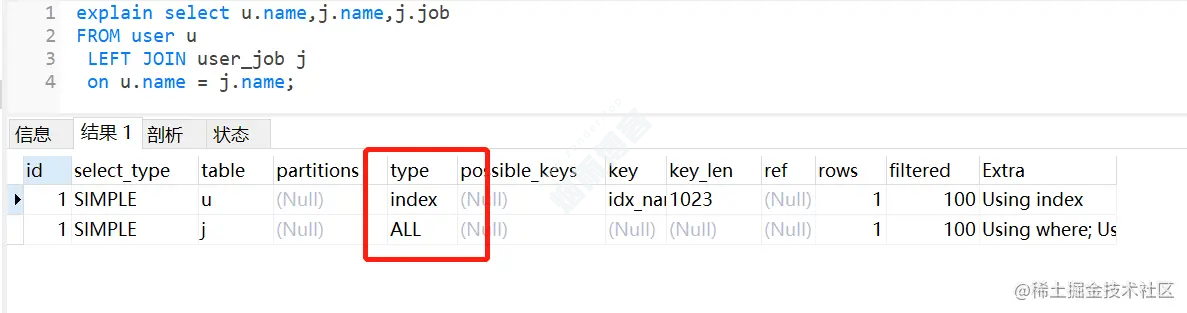
执行左外连接查询,user_job表还是走全表扫描,如下:
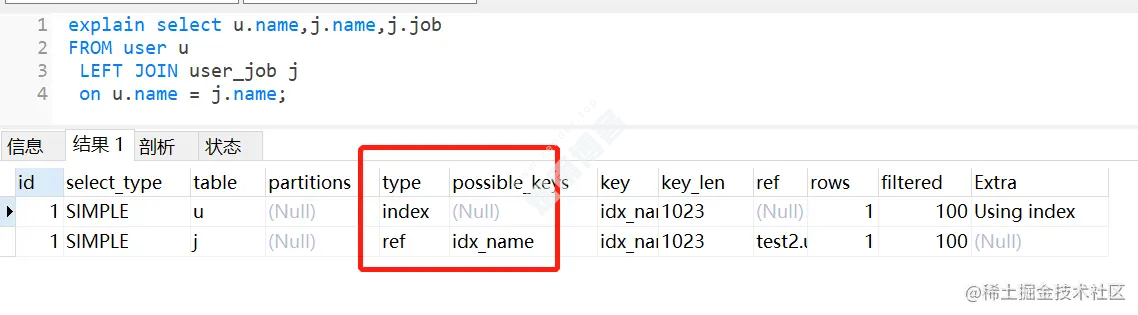
如果把它们的name字段改为编码一致,相同的SQL,还是会走索引。
2.10 优化器选错了索引
MySQL 中一张表是可以支持多个索引的。你写SQL语句的时候,没有主动指定使用哪个索引的话,用哪个索引是由MySQL来确定的。
我们日常开发中,不断地删除历史数据和新增数据的场景,有可能会导致MySQL选错索引。那么有哪些解决方案呢?
使用
force index强行选择某个索引修改你的SQl,引导它使用我们期望的索引
优化你的业务逻辑
优化你的索引,新建一个更合适的索引,或者删除误用的索引。
3. limit深分页问题
CREATE TABLE account ( id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', name varchar(255) DEFAULT NULL COMMENT '账户名', balance int(11) DEFAULT NULL COMMENT '余额', create_time datetime NOT NULL COMMENT '创建时间', update_time datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (id), KEY idx_name (name), KEY idx_create_time (create_time) //索引 ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';
你知道以下SQL,执行过程是怎样的嘛?
select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;
这个SQL的执行流程:
通过普通二级索引树
idx_create_time,过滤create_time条件,找到满足条件的主键id。通过
主键id,回到id主键索引树,找到满足记录的行,然后取出需要展示的列(回表过程)扫描满足条件的
100010行,然后扔掉前100000行,返回。

limit深分页,导致SQL变慢原因有两个:limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。也就是说limit 100000,10,就会扫描100010行,而limit0,10,只扫描10行。limit 100000,10扫描更多的行数,也意味着回表更多的次数。
3.2 如何优化深分页问题
100000,则SQL可以修改为:select id,name,balance FROM account where id > 100000 limit 10;
id索引。但是这种方式有局限性:需要一种类似连续自增的字段。select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 ON acct1.id= acct2.id;
idx_create_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。4. 单表数据量太大
4.1 单表数据量太大为什么会变慢?
B+树结构层级变得更高了,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢。4.2 一棵B+树可以存多少数据量
16k。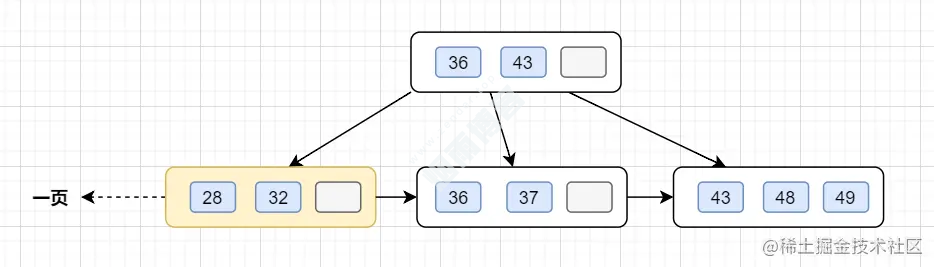
2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16.
- 非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(面试官问你int类型,一个int就是32位,4字节),而指针大小在InnoDB源码中设置为6字节,所以就是8+6=14字节,16k/14B =16*1024B/14B = 1170
1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,也就是说,可以存放两千万左右的记录。B+树高度一般为1-3层,已经满足千万级别的数据存储。4.3 如何解决单表数据量太大,查询变慢的问题
一般超过千万级别,我们可以考虑分库分表了。
分库分表可能导致的问题:
事务问题
跨库问题
排序问题
分页问题
分布式ID
5. join 或者子查询过多
join来优化。而数据库有个规范约定就是:尽量不要有超过3个以上的表连接。为什么要这么建议呢? 我们来聊聊,join哪些方面可能导致慢查询吧。Index Nested-Loop Join和Block Nested-Loop Join。Index Nested-Loop Join:这个join算法,跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引。Block Nested-Loop Join:这种join算法,被驱动表上没有可用的索引,它会先把驱动表的数据读入线程内存join_buffer中,再扫描被驱动表,把被驱动表的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
join过多的问题:join_buffer内存做的,如果匹配的数据量比较小或者join_buffer设置的比较大,速度也不会太慢。但是,如果join的数据量比较大时,mysql会采用在硬盘上创建临时表的方式进行多张表的关联匹配,这种显然效率就极低,本来磁盘的 IO 就不快,还要关联。2~3个表是可以接受的,但是关联的字段需要加索引哈。如果需要关联更多的表,建议从代码层面进行拆分,在业务层先查询一张表的数据,然后以关联字段作为条件查询关联表形成map,然后在业务层进行数据的拼装。6. in元素过多
in,即使后面的条件加了索引,还是要注意in后面的元素不要过多哈。in元素一般建议不要超过500个,如果超过了,建议分组,每次500一组进行哈。select user_id,name from user where user_id in (1,2,3...1000000);
如果我们对in的条件不做任何限制的话,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。尤其有时候,我们是用的子查询,in后面的子查询,你都不知道数量有多少那种,更容易采坑(所以我把in元素过多抽出来作为一个小节)。如下这种子查询:
select * from user where user_id in (select author_id from artilce where type = 1);
正例是,分批进行,每批500个:
select user_id,name from user where user_id in (1,2,3...500);
如果传参的ids太多,还可以做个参数校验什么的
if (userIds.size() > 500) {
throw new Exception("单次查询的用户Id不能超过200");
}7. 数据库在刷脏页
7.1 什么是脏页
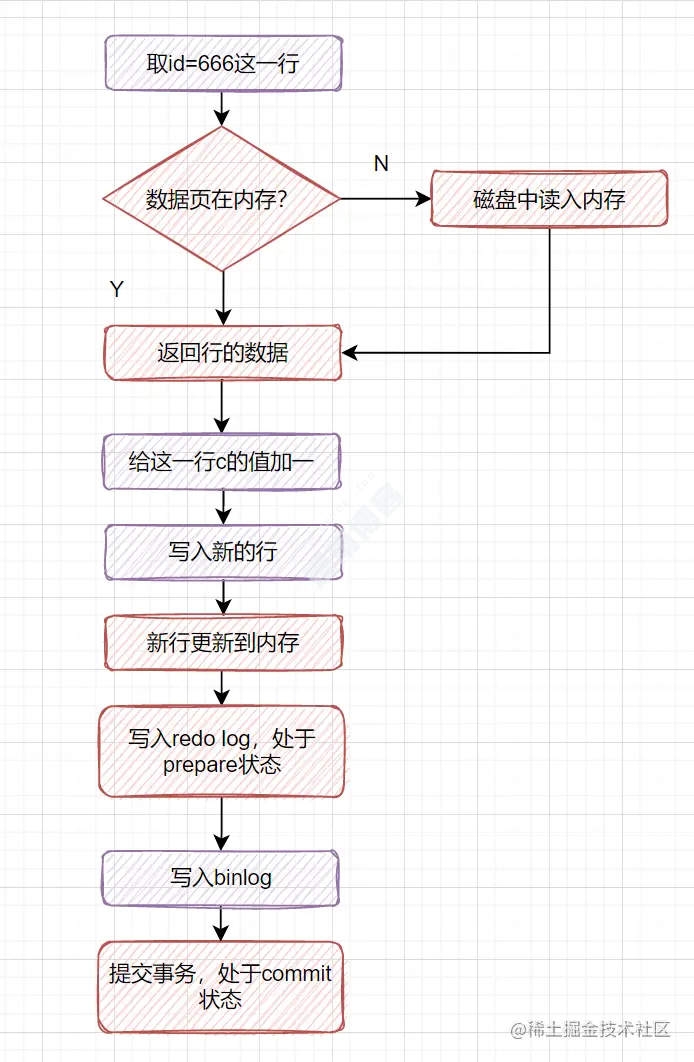
7.2 一条更新语句是如何执行的?
update t set c=c+1 where id=666;
对于这条更新SQL,执行器会先找引擎取
id=666这一行。如果这行所在的数据页本来就在内存中的话,就直接返回给执行器。如果不在内存,就去磁盘读入内存,再返回。执行器拿到引擎给的行数据后,给这一行
C的值加一,得到新的一行数据,再调用引擎接口写入这行新数据。引擎将这行新数据更新到内存中,同时将这个更新操作记录到
redo log里面,但是此时redo log是处于prepare状态的哈。执行器生成这个操作的
binlog,并把binlog写入磁盘。执行器调用引擎的提交事务接口,引擎把刚刚写入的
redo log改成提交(commit)状态,更新完成。
redo log(重做日志)。平时更新SQL执行得很快,其实是因为它只是在写内存和redo log日志,等到空闲的时候,才把redo log日志里的数据同步到磁盘中。7.3 为什么会出现脏页呢?
redo log日志,等到空闲的时候,才把redo log日志里的数据同步到磁盘中。这时内存数据页跟磁盘数据页内容不一致,我们称之为脏页。7.4 什么时候会刷脏页(flush)?
redo log大小是固定,且是环型写入的,如下图(图片来源于MySQL 实战 45 讲):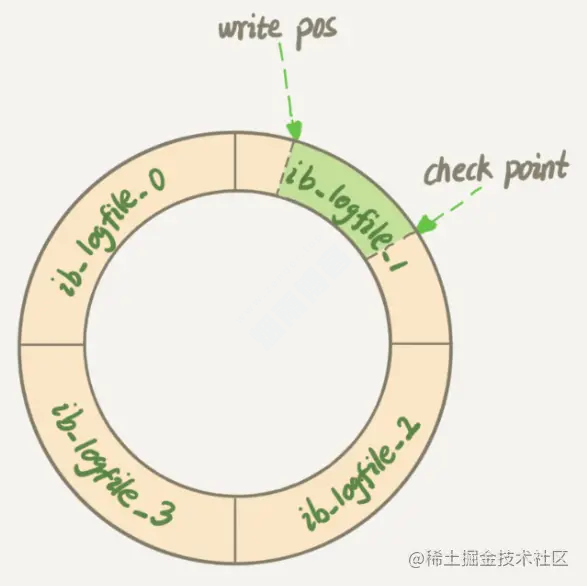
redo log写满了,要刷脏页。这种情况要尽量避免的。因为出现这种情况时,整个系统就不能再接受更新啦,即所有的更新都必须堵住。内存不够了,需要新的内存页,就要淘汰一些数据页,这时候会刷脏页
InnoDB 用缓冲池(buffer pool)管理内存,而当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页呢,就必须将脏页先刷到磁盘,变成干净页后才能复用。
MySQL 认为系统空闲的时候,也会刷一些脏页
MySQL 正常关闭时,会把内存的脏页都 flush 到磁盘上
7.5 为什么刷脏页会导致SQL变慢呢?
redo log写满了,要刷脏页,这时候会导致系统所有的更新堵住,写性能都跌为0了,肯定慢呀。一般要杜绝出现这个情况。一个查询要淘汰的脏页个数太多,一样会导致查询的响应时间明显变长。
8. order by 文件排序
order by就一定会导致慢查询吗?不是这样的哈,因为order by平时用得多,并且数据量一上来,还是走文件排序的话,很容易有慢SQL的。听我娓娓道来,order by哪些时候可能会导致慢SQL哈。8.1 order by 的 Using filesort文件排序
order by ,主要就是用来给某些字段排序的。比如以下SQL:select name,age,city from staff where city = '深圳' order by age limit 10;
它表示的意思就是:查询前10个,来自深圳员工的姓名、年龄、城市,并且按照年龄小到大排序。

explain执行计划的时候,可以看到Extra这一列,有一个Using filesort,它表示用到文件排序。8.2 order by文件排序效率为什么较低
order by用到文件排序时,为什么查询效率会相对低呢?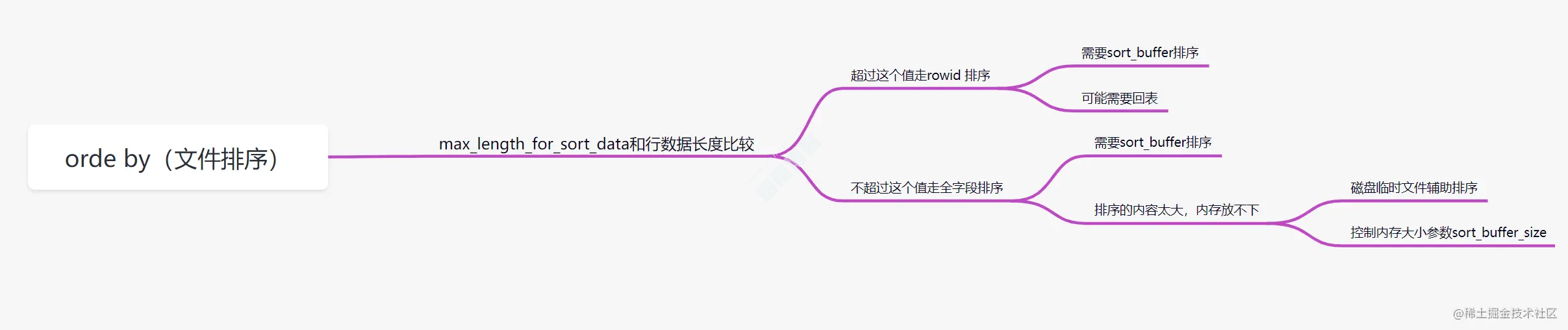
order by的文件排序,分为全字段排序和rowid排序。它是拿max_length_for_sort_data和结果行数据长度对比,如果结果行数据长度超过max_length_for_sort_data这个值,就会走rowid排序,相反,则走全字段排序。rowid排序
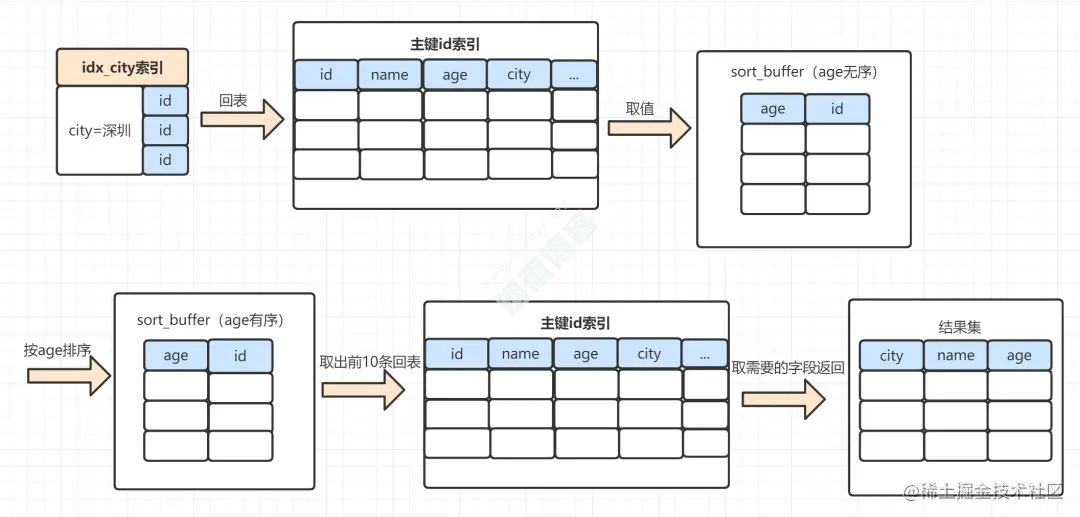
rowid排序,执行过程是这样:select name,age,city from staff where city = '深圳' order by age limit 10;
MySQL 为对应的线程初始化
sort_buffer,放入需要排序的age字段,以及主键id;从索引树
idx_city, 找到第一个满足city='深圳’条件的主键id,也就是图中的id=9;到
主键id索引树拿到id=9的这一行数据, 取age和主键id的值,存到sort_buffer;从索引树
idx_city拿到下一个记录的主键id,即图中的id=13;重复步骤 3、4 直到
city的值不等于深圳为止;前面5步已经查找到了所有
city为深圳的数据,在sort_buffer中,将所有数据根据age进行排序;遍历排序结果,取前10行,并按照
id的值回到原表中,取出city、name 和 age三个字段返回给客户端。
全字段排序
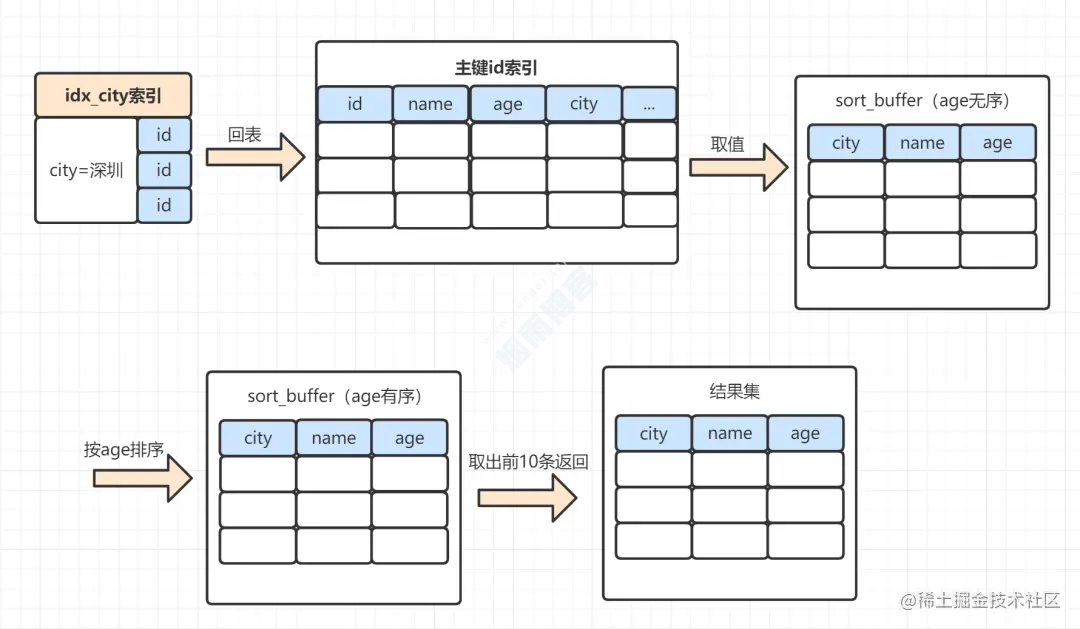
select name,age,city from staff where city = '深圳' order by age limit 10;
MySQL 为对应的线程初始化
sort_buffer,放入需要查询的name、age、city字段;从索引树
idx_city, 找到第一个满足city='深圳’条件的主键 id,也就是图中的id=9;到主键
id索引树拿到id=9的这一行数据, 取name、age、city三个字段的值,存到sort_buffer;从索引树
idx_city拿到下一个记录的主键id,即图中的id=13;重复步骤 3、4 直到
city的值不等于深圳为止;前面5步已经查找到了所有
city为深圳的数据,在sort_buffer中,将所有数据根据age进行排序;按照排序结果取前10行返回给客户端。
sort_buffer的大小是由一个参数控制的:sort_buffer_size。如果要排序的数据小于
sort_buffer_size,排序在sort_buffer内存中完成如果要排序的数据大于
sort_buffer_size,则借助磁盘文件来进行排序。
sort_buffer,当快要满时。会排一下序,然后把sort_buffer中的数据,放到临时磁盘文件,等到所有满足条件数据都查完排完,再用归并算法把磁盘的临时排好序的小文件,合并成一个有序的大文件。8.3 如何优化order by的文件排序
order by使用文件排序,效率会低一点。我们怎么优化呢?因为数据是无序的,所以就需要排序。如果数据本身是有序的,那就不会再用到文件排序啦。而索引数据本身是有序的,我们通过建立索引来优化
order by语句。我们还可以通过调整
max_length_for_sort_data、sort_buffer_size等参数优化;
9. 拿不到锁
show processlist命令,看看当前语句处于什么状态哈。10. delete + in子查询不走索引!
delete遇到in子查询时,即使有索引,也是不走索引的。而对应的select + in子查询,却可以走索引。CREATE TABLE `old_account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='老的账户表'; CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';
执行的SQL如下:
delete from account where name in (select name from old_account);
查看执行计划,发现不走索引:

但是如果把delete换成select,就会走索引。如下:

select + in子查询会走索引,delete + in子查询却不会走索引呢?explain select * from account where name in (select name from old_account); show WARNINGS; //可以查看优化后,最终执行的sql
结果如下:
select `test2`.`account`.`id` AS `id`,`test2`.`account`.`name` AS `name`,`test2`.`account`.`balance` AS `balance`,`test2`.`account`.`create_time` AS `create_time`,`test2`.`account`.`update_time` AS `update_time` from `test2`.`account` semi join (`test2`.`old_account`) where (`test2`.`account`.`name` = `test2`.`old_account`.`name`)
select in子查询做了优化,把子查询改成join的方式,所以可以走索引。但是很遗憾,对于delete in子查询,MySQL却没有对它做这个优化。11、group by使用临时表
group by一般用于分组统计,它表达的逻辑就是根据一定的规则,进行分组。日常开发中,我们使用得比较频繁。如果不注意,很容易产生慢SQL。11.1 group by的执行流程
CREATE TABLE `staff` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `id_card` varchar(20) NOT NULL COMMENT '身份证号码', `name` varchar(64) NOT NULL COMMENT '姓名', `age` int(4) NOT NULL COMMENT '年龄', `city` varchar(64) NOT NULL COMMENT '城市', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';
我们查看一下这个SQL的执行计划:
explain select city ,count(*) as num from staff group by city;

Extra 这个字段的
Using temporary表示在执行分组的时候使用了临时表xtra 这个字段的
Using filesort表示使用了文件排序
group by是怎么使用到临时表和排序了呢?我们来看下这个SQL的执行流程
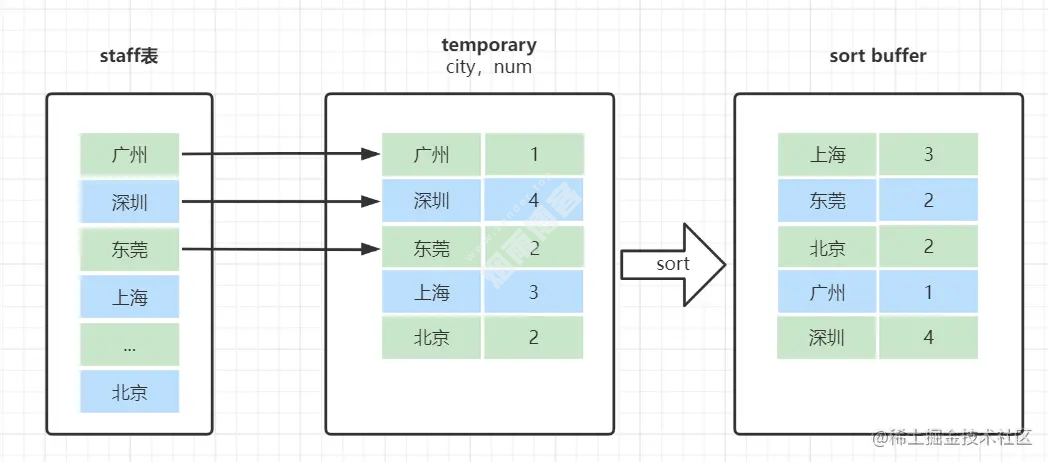
select city ,count(*) as num from staff group by city;
创建内存临时表,表里有两个字段
city和num;全表扫描
staff的记录,依次取出city = 'X'的记录。判断临时表中是否有为
city='X'的行,没有就插入一个记录(X,1);如果临时表中有
city='X'的行,就将X这一行的num值加 1;遍历完成后,再根据字段
city做排序,得到结果集返回给客户端。 这个流程的执行图如下:
临时表的排序是怎样的呢?
就是把需要排序的字段,放到sort buffer,排完就返回。在这里注意一点哈,排序分全字段排序和rowid排序
如果是全字段排序,需要查询返回的字段,都放入sort buffer,根据排序字段排完,直接返回
如果是rowid排序,只是需要排序的字段放入sort buffer,然后多一次回表操作,再返回。
11.2 group by可能会慢在哪里?
group by使用不当,很容易就会产生慢SQL 问题。因为它既用到临时表,又默认用到排序。有时候还可能用到磁盘临时表。如果执行过程中,会发现
内存临时表大小到达了上限(控制这个上限的参数就是tmp_table_size),会把内存临时表转成磁盘临时表。如果数据量很大,很可能这个查询需要的磁盘临时表,就会占用大量的磁盘空间。
11.3 如何优化group by呢?
方向1:既然它默认会排序,我们不给它排是不是就行啦。
方向2:既然临时表是影响group by性能的X因素,我们是不是可以不用临时表?
group by语句为什么需要临时表呢?group by的语义逻辑,就是统计不同的值出现的个数。如果这个这些值一开始就是有序的,我们是不是直接往下扫描统计就好了,就不用临时表来记录并统计结果啦?可以有这些优化方案:
group by 后面的字段加索引
order by null 不用排序
尽量只使用内存临时表
使用SQL_BIG_RESULT
12. 系统硬件或网络资源
如果数据库服务器内存、硬件资源,或者网络资源配置不是很好,就会慢一些哈。这时候可以升级硬件配置。这就好比你的计算机有时候很卡,你可以加个内存条什么的一个道理。
如果数据库压力本身很大,比如高并发场景下,大量请求到数据库来,数据库服务器
CPU占用很高或者IO利用率很高,这种情况下所有语句的执行都有可能变慢的哈。这时候你开始排查是不是出什么问题啦。
版权声明
非特殊说明,本文由Zender原创或收集发布,欢迎转载。


作者文章
- MyBatisCodeHelper-Pro3.3.6+2321破解 2年前 (2024-10-17)
- 网站迁移公告 2年前 (2024-10-10)
- Java项目防止SQL注入4总方式 3年前 (2023-09-06)
- JAVA开发小技巧--读取文件魔数来识别文件类型 3年前 (2023-08-24)
- 分类树菜单优化 3年前 (2023-08-22)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。