3、Redis 主从复制
一、什么是主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。
前者称为主节点(Master),后者称为从节点(Slave)。
数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
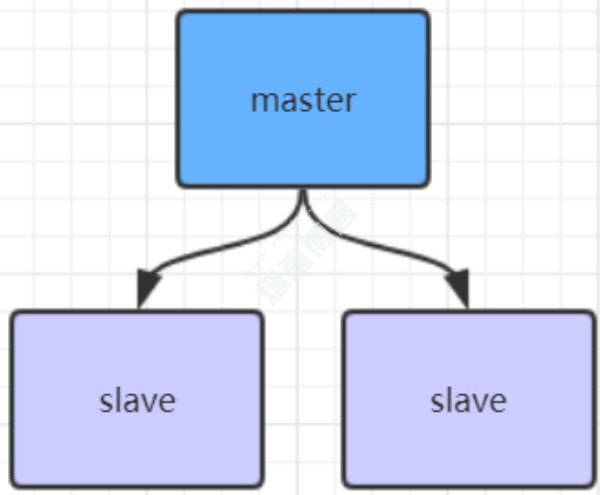
二、主从复制作用
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
读写分离:可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量。
三、配置
配置文件: 在从服务器的配置文件中加入:slaveof IP 端口号
启动命令: redis-server启动命令后加入 --slaveof IP 端口号
客户端命令: Redis服务器启动后,通过./redis-cli连接Redis,执行命令:slaveof IP 端口号(则该Redis实例成为从节点)。
Redis主从结构支持一主多从
主节点:192.168.181.128:6379
从节点:192.168.181.128:6380
只需要在从节点redis.conf中配置slaveof属性,指定主节点ip+端口号。
slaveof 192.168.181.128 6379
如果主节点设置了密码,也需要在从节点配置,相当于做了一个免密码登录。
# 123456改成自己Redis的密码 masterauth 123456
[root@Zender src]# ./redis-cli -p 6379 -a 123456 Warning: Using a password with '-a' option on the command line interface may not be safe. 127.0.0.1:6379> INFO Replication # Replication role:master #--------------->节点状态为主节点(master) connected_slaves:1 #--------------->子节点个数 slave0:ip=192.168.181.128,port=6380,state=online,offset=1498,lag=0 #--------------->子节节点0 master_replid:71cf4c1d2f3b51b364d658da6063accc73299e26 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1498 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1498
查看子节点配置
# -h IP地址 -p 端口号 -a 密码 [root@Zender src]# ./redis-cli -p 6380 -a 123456 Warning: Using a password with '-a' option on the command line interface may not be safe. 127.0.0.1:6380> INFO Replication # Replication role:slave #--------------->节点状态为子节点(slave) master_host:192.168.181.128 #--------------->连接的主节点的IP地址 master_port:6379 #--------------->连接的主节点的端口号 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:1288 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:71cf4c1d2f3b51b364d658da6063accc73299e26 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1288 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1288
四、Redis主从工作原理
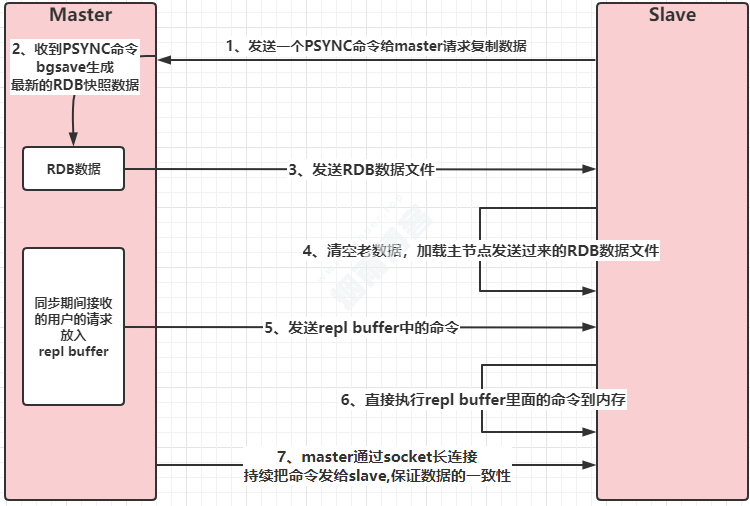
4.1、主从复制(全量复制)流程图
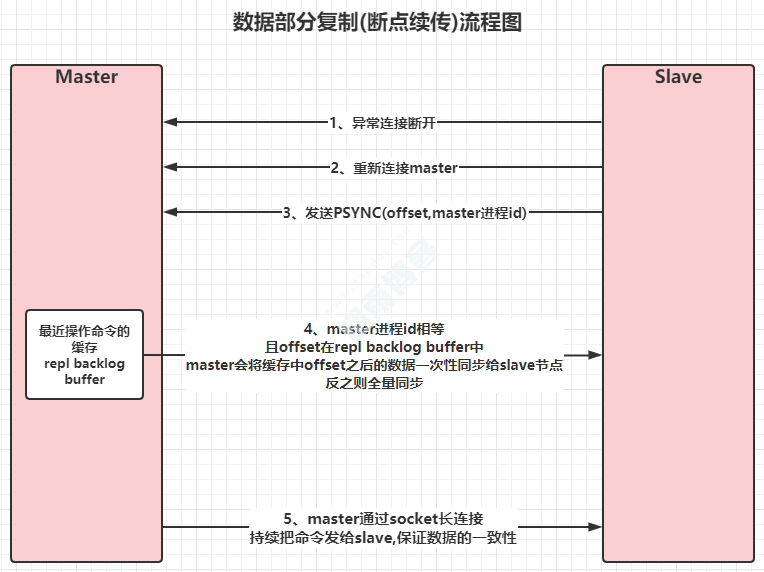
4.2、数据部分复制(断点续传)流程图
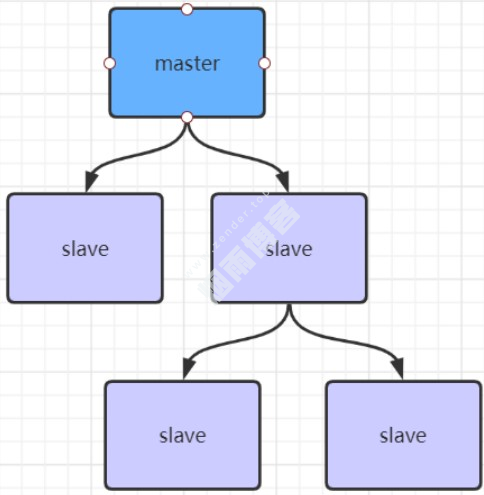
4.3、主从复制风暴
五、Jedis连接代码示例
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency>
public class JedisSingleTest {
public static void main(String[] args) throws IOException {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMinIdle(5);
// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.0.60", 6379, 3000, null);
Jedis jedis = null;
try {
//从redis连接池里拿出一个连接执行命令
jedis = jedisPool.getResource();
System.out.println(jedis.set("single", "zhuge"));
System.out.println(jedis.get("single"));
//管道示例
//管道的命令执行方式:cat redis.txt | redis-cli -h 127.0.0.1 -a password - p 6379 --pipe
for (int i = 0; i < 10; i++) {
pl.incr("pipelineKey");
pl.set("zhuge" + i, "zhuge");
}
List<Object> results = pl.syncAndReturnAll();
System.out.println(results);
//lua脚本模拟一个商品减库存的原子操作
//lua脚本命令执行方式:redis-cli --eval /tmp/test.lua , 10
jedis.set("product_count_10016", "15"); //初始化商品10016的库存
String script = " local count = redis.call('get', KEYS[1]) " +
" local a = tonumber(count) " +
" local b = tonumber(ARGV[1]) " +
" if a >= b then " +
" redis.call('set', KEYS[1], a-b) " +
" return 1 " +
" end " +
" return 0 ";
Object obj = jedis.eval(script, Arrays.asList("product_count_10016"), Arrays.asList("10"));
System.out.println(obj);
} catch (Exception e) {
e.printStackTrace();
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if (jedis != null)
jedis.close();
}
}
}5.1、管道(Pipeline)
Pipeline pl = jedis.pipelined();
for (int i = 0; i < 10; i++) {
pl.incr("pipelineKey");
pl.set("zhuge" + i, "zhuge");
//模拟管道报错
// pl.setbit("zhuge", -1, true);
pl.set("wanglang" + i, "wanglang");
}
List<Object> results = pl.syncAndReturnAll();
System.out.println(results);5.2、Lua脚本
减少网络开销:本来5次网络请求的操作,可以用一个请求完成,原先5次请求的逻辑放在redis服务器上完成。使用脚本,减少了网络往返时延。这点跟管道类似。
原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。管道不是原子的,不过redis的批量操作命令(类似mset)是原子的。
替代redis的事务功能:redis自带的事务功能很鸡肋,而redis的lua脚本几乎实现了常规的事务功能,官方推荐如果要使用redis的事务功能可以用redis lua替代。
EVAL script numkeys key [key ...] arg [arg ...]
script参数:是一段Lua脚本程序,它会被运行在Redis服务器上下文中,这段脚本不必(也不应该)定义为一个Lua函数。
numkeys参数:用于指定键名参数的个数。
key [key ...] 键名参数:从EVAL的第三个参数开始算起,表示在脚本中所用到的那些Redis键(key),这些键名参数可以在 Lua中通过全局变量KEYS数组,用1为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推)。
arg [arg ...] 附加参数:可以在Lua中通过全局变量ARGV数组访问,访问的形式和KEYS变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)。
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"jedis.set("product_stock_10016", "15"); //初始化商品10016的库存为15个
String script = " local count = redis.call('get', KEYS[1]) " +
" local a = tonumber(count) " +
" local b = tonumber(ARGV[1]) " +
" if a >= b then " +
" redis.call('set', KEYS[1], a-b) " +
" return 1 " +
" end " +
" return 0 ";
Object obj = jedis.eval(script, Arrays.asList("product_stock_10016"), Arrays.asList("10"));
System.out.println(obj);注意:不要在Lua脚本中出现死循环和耗时的运算,否则redis会阻塞,将不接受其他的命令, 所以使用时要注意不能出现死循环、耗时的运算。redis是单进程、单线程执行脚本。管道不会阻塞redis。
版权声明
非特殊说明,本文由Zender原创或收集发布,欢迎转载。


作者文章
- MyBatisCodeHelper-Pro3.3.6+2321破解 1年前 (2024-10-17)
- 网站迁移公告 2年前 (2024-10-10)
- Java项目防止SQL注入4总方式 3年前 (2023-09-06)
- JAVA开发小技巧--读取文件魔数来识别文件类型 3年前 (2023-08-24)
- 分类树菜单优化 3年前 (2023-08-22)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。