2、volatile关键字
一、认识volatile关键字
public class VolatileDemo01 {
final static int MAX = 50;
static int initValue = 0;
public static void main(String[] args) {
//读取值的线程
new Thread(() -> {
int localValue = initValue;
while (localValue < MAX) {
if (localValue != initValue) {
System.out.println("Reader:" + initValue);
localValue = initValue;
}
}
}, "Reader").start();
//修改值的线程
new Thread(() -> {
int localValue = initValue;
while (localValue < MAX) {
System.out.println("Updater:" + (++localValue));
initValue = localValue;
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "Updater").start();
}
}1.1、未加volatile关键字时,运行结果

1.2、加volatile关键字时,运行结果
static volatile int initValue = 0;

二、CPU Cache
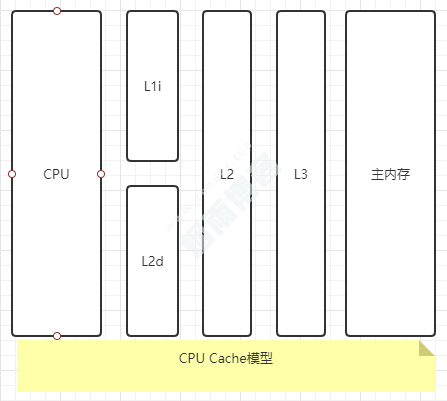
2.1、CPU通过Cache与主内存的交互方式

CPU先从CPU寄存器获取资源。若没获取到,通过Cache中获取。若没获取到,通过主内存获取。
获取到主内存资源时,复制一份到Cache中,再复制一份到寄存器中(寄存器存放的是当前CPU环境以及任务环境的数据,也就是需要修改的数据)。
CPU修改数据后,结果回写到CPU Cache中。
CPU Cache再将数据刷新到主内存中。
2.2、数据不一致问题
三、解决数据不一致问题方案
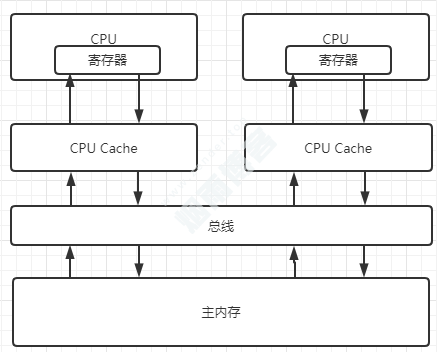
3.1、总线加锁方式
3.2、缓存一致性协议(MESI)
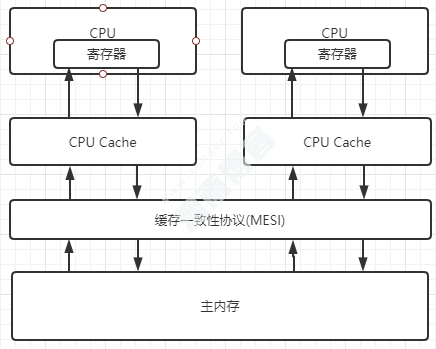
其大致思想是,当CPU在操作Cache中的数据时,如果发现该变量是一个共享变量,也就是在其他CPU Cache中也存在一个副本,那么执行以下操作:
读取操作时:不做任何处理,只是将Cache中的数据读取到寄存器。
写入操作时:发出信号通知其他CPU将该变量的Cache line置为无效状态,写入成功后,此时其他CPU通过总线嗅探机制得知写入成功,就再次从主存中获取该共享变量。
缓存一致性协议内容很复杂,这里只是大致描述了过程。
四、volatile的禁止重排优化
4.1、硬件层的内存屏障
lfence:是一种Load Barrier读屏障。
sfence:是一种Store Barrier 写屏障。
mfence:是一种全能型的屏障,具备ifence和sfence的能力。
Lock前缀:Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。
public class DoubleCheckLock {
private static DoubleCheckLock instance;
private DoubleCheckLock(){}
public static DoubleCheckLock getInstance(){
//第一次检测
if (instance==null){
//同步
synchronized (DoubleCheckLock.class){
if (instance == null){
//多线程环境下可能会出现问题的地方
instance = new DoubleCheckLock();
}
}
}
return instance;
}
}// 1.分配对象内存空间 memory = allocate(); // 2.初始化对象 instance(memory); // 3.设置instance指向刚分配的内存地址,此时instance!=null instance = memory;
步骤1和步骤2间可能会重排序,如下:
// 1.分配对象内存空间 memory=allocate(); // 3.设置instance指向刚分配的内存地址,此时instance!=null,但是对象还没有初始化完成! instance=memory; // 2.初始化对象 instance(memory);
// volatile禁止指令重排优化 private volatile static DoubleCheckLock instance;
4.2、volatile内存语义
当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能进行重排。
当第一个操作为volatile读时,第二个操作无论是什么都不能进行重排(这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前)。
当第一个操作是volatile写,第二个操作是volatile读volatile写时,不能进行重排。
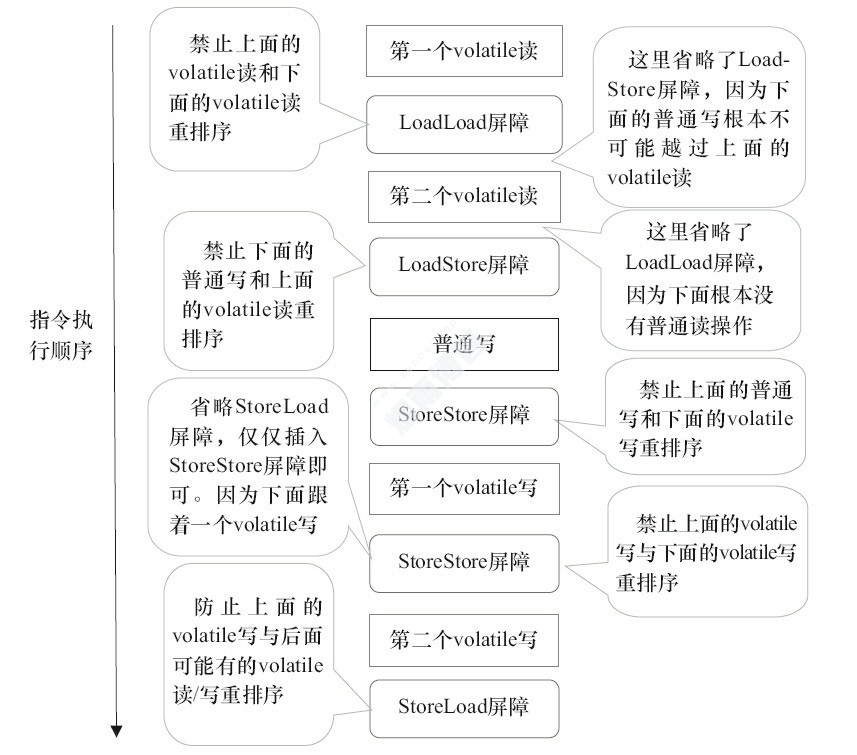
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的后面插入一个Store Load屏障。
在每个volatile读操作的后面插入一个Load Load屏障和Load Store屏障。
volatile写插入内存屏障后生成的指令序列示意图
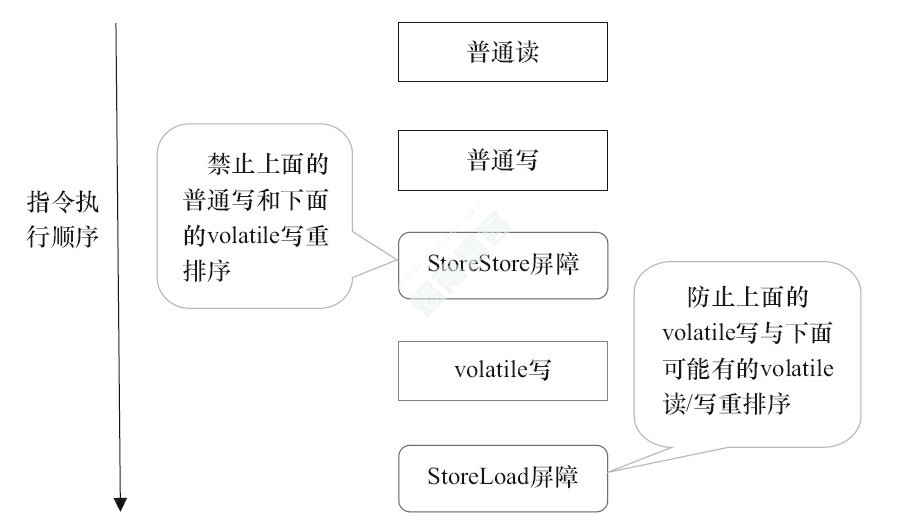
volatile读插入内存屏障后生成的指令序列示意图

class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; // 第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; // 普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; // 第二个 volatile写
}
}针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化:

版权声明
非特殊说明,本文由Zender原创或收集发布,欢迎转载。


作者文章
- MyBatisCodeHelper-Pro3.3.6+2321破解 2年前 (2024-10-17)
- 网站迁移公告 2年前 (2024-10-10)
- Java项目防止SQL注入4总方式 3年前 (2023-09-06)
- JAVA开发小技巧--读取文件魔数来识别文件类型 3年前 (2023-08-24)
- 分类树菜单优化 3年前 (2023-08-22)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。