1,MySQL 索引
一、数据库三范式
第一范式(1NF):字段具有原子性,不可再分。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的:为表加上一个列,以存储实例的惟一标识(就是主键)。
满足第三范式(3NF)必须先满足第二范式(2NF):每一个表都不包含其他表已经包含的非主关键字信息。
二、索引有哪些种类
普通索引:即针对数据库表创建索引。
唯一索引:与普通索引类似,不同的就是:MySQL数据库索引列的值必须唯一,但允许有空值。
主键索引:它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。
联合索引:为了进一步榨取MySQL的效率,就要考虑建立联合索引。即将数据库表中的多个字段联合起来作为一个联合索引。
三、索引的工作机制(底层原理)
索引其实是摆好序的数据结构,方便mysql去查找。
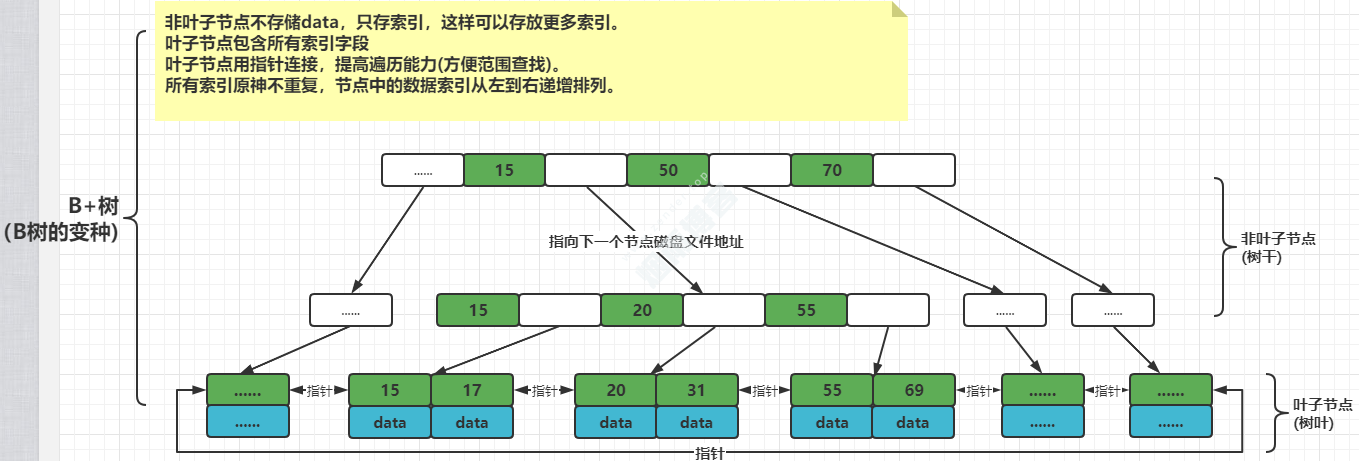
索引数据结构:使用的是B+树。
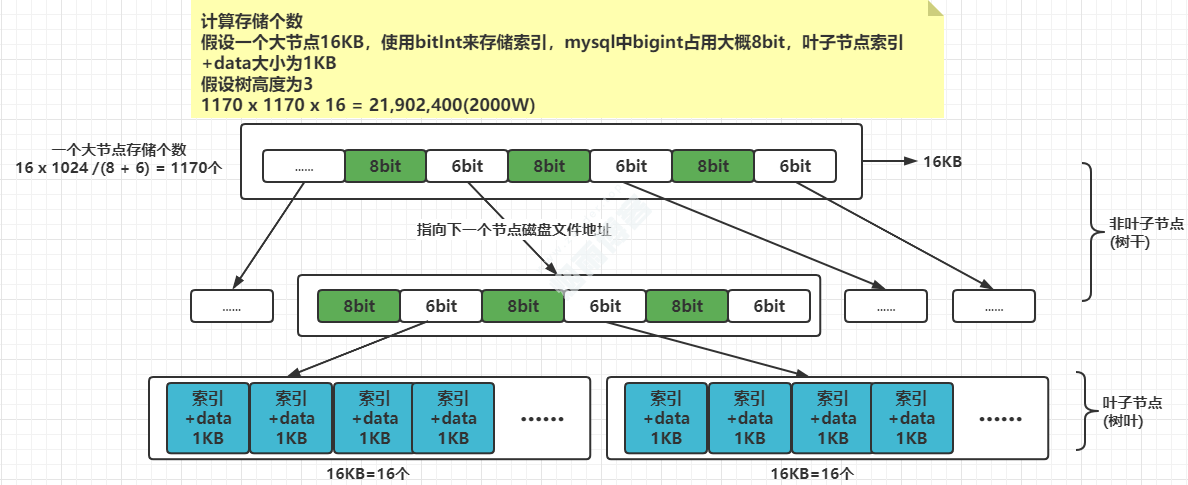
树查询效率和树的高度有关
3.1、二叉树
弊端:通常我们的表主键字段都是自增的,单边增长,导致二叉树只有右节点。树太高,遍历效率慢。
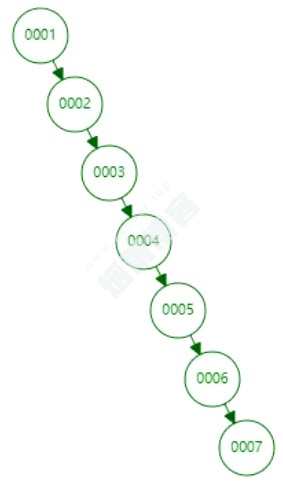
3.2、红黑树
弊端:虽然做了平衡,但是数据量大了,树也太高,遍历效率慢。
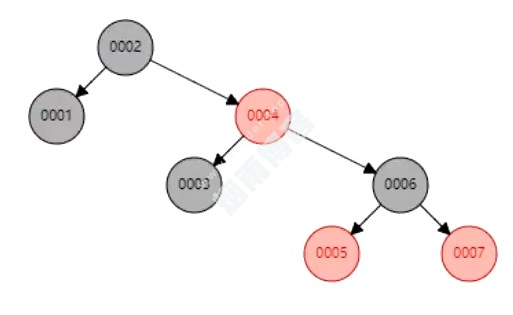
3.3、B树
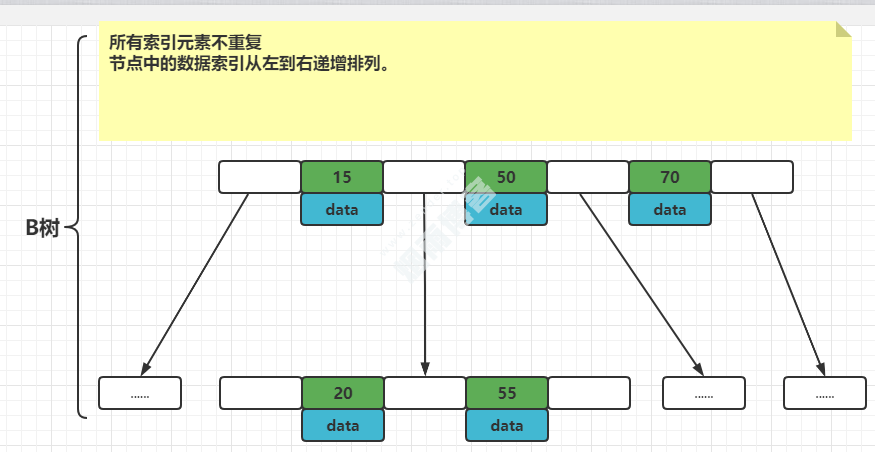
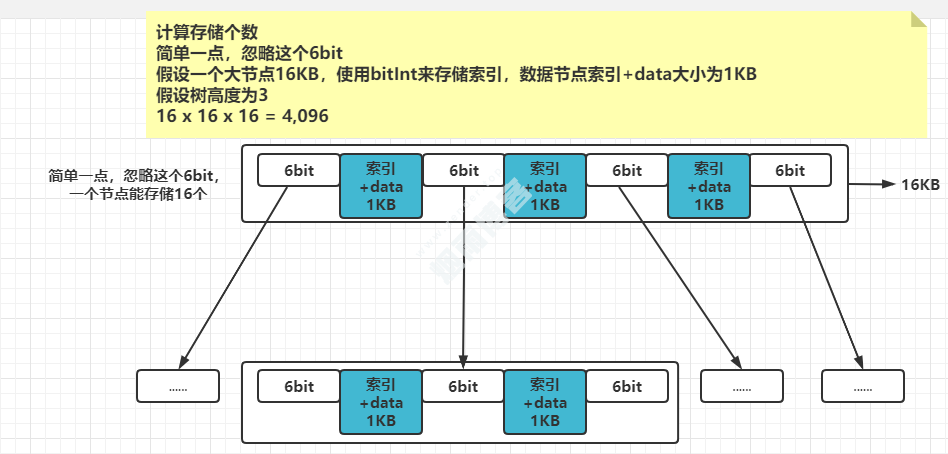
3.4、B+树
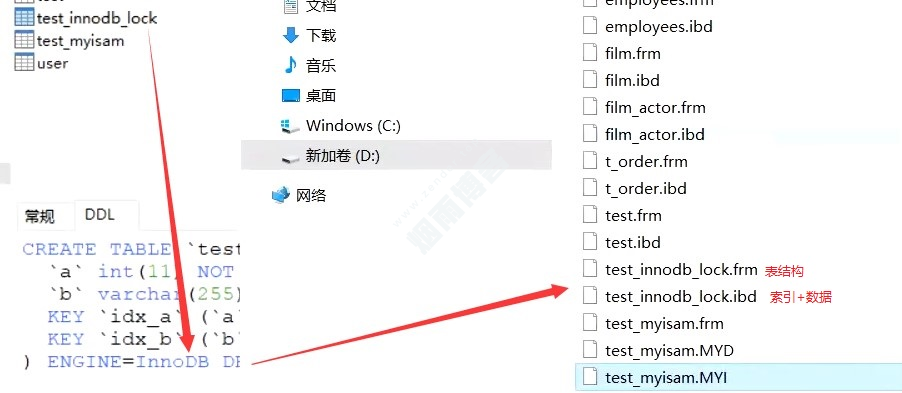
四、myISAM、InnoDB存储引擎索引存储方式
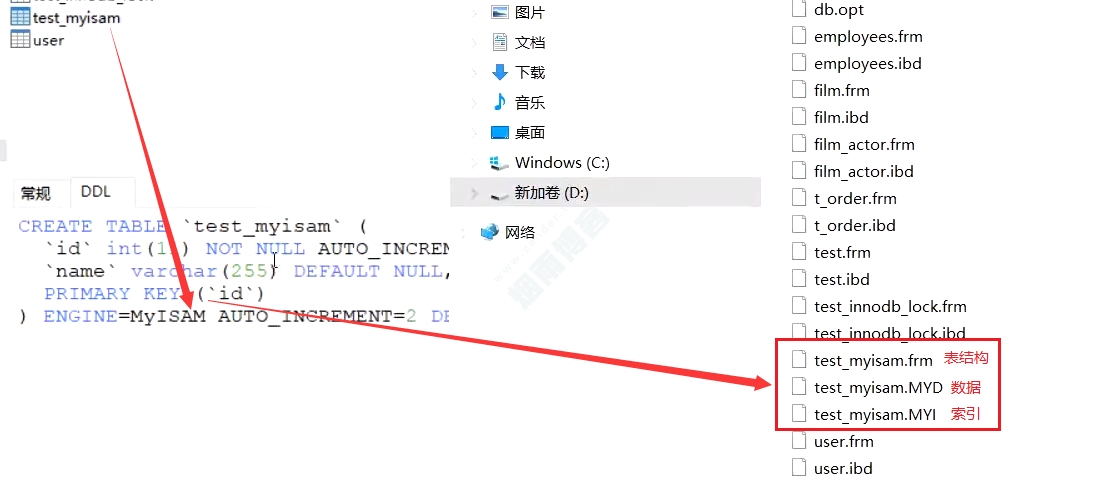
4.1、myISAM
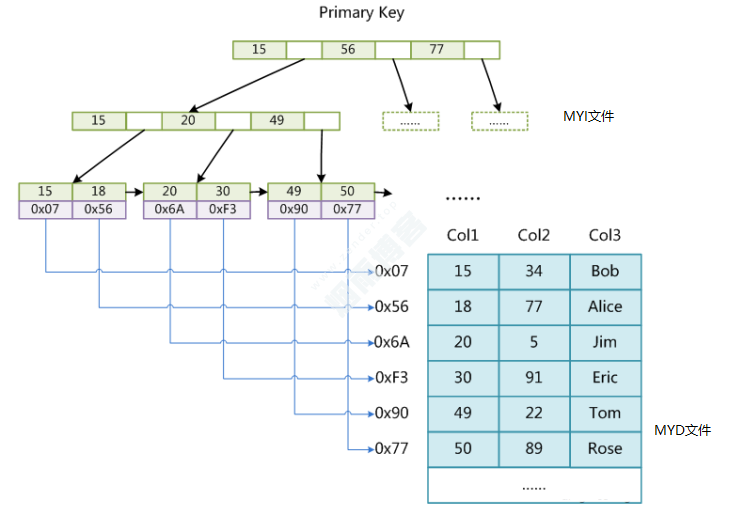
存储方式如图(非聚集索引)
如果查找Col1 = 30时,首先进入MYI文件,从b+树头节点开始遍历,查找Col1 = 30,获取到存储内存地址,去MYD文件去拿对应数据。
访问了2次磁盘,才能拿到数据。
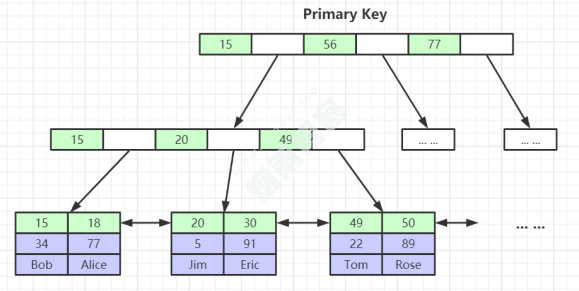
4.2、InnoDB
存储方式如图
InnoDB索引实现(聚集索引)
表数据文件本身就是按B+Tree组织的一个索引结构文件,聚集索引-叶节点包含了完整的数据记录。
访问一次磁盘就能拿到数据。
如果没有主键,那么会选择唯一键,如果唯一键都没有,会隐试的生成一个6位的row_id来作为主键。
4.2.1、建立非主键索引的结构
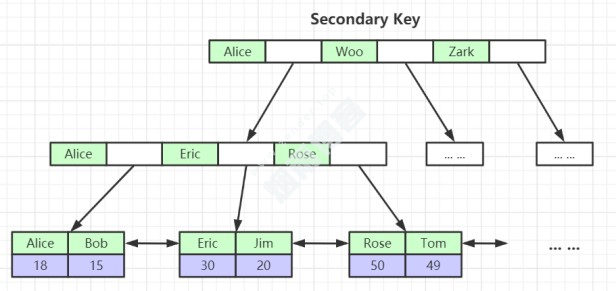
为什么非主键索引结构叶子节点只存储了主键值?
一致性和节省存储空间。
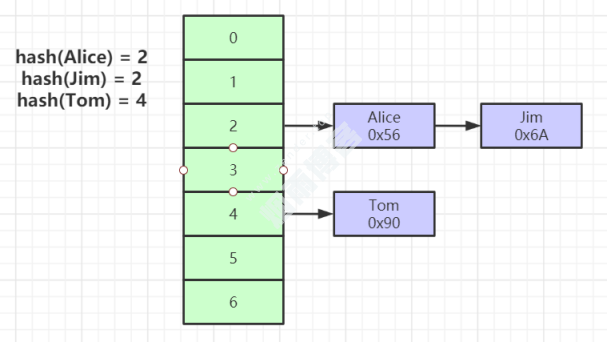
五、Hash索引
对索引的key进行一次hash计算就可以定位出数据存储的位置。
很多时候Hash索引要比B+ 树索引更高效。
仅能满足 “=”,“IN”,不支持范围查询。
hash冲突问题。
六、联合索引数据结构
这里建立了一个联合主键索引
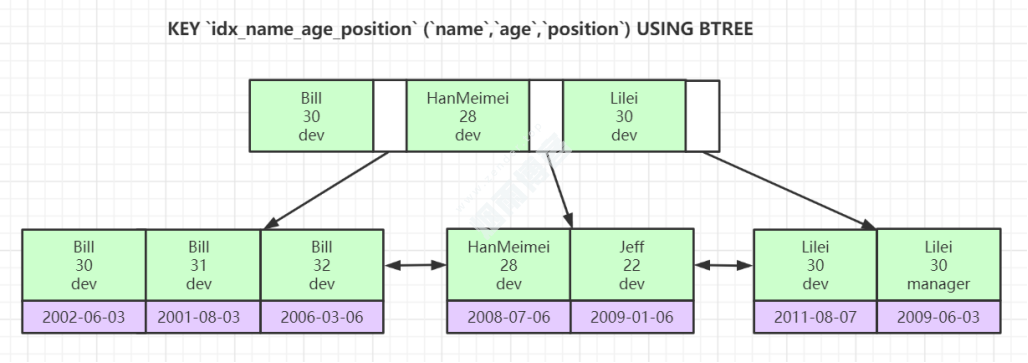

根据索引最左前原理,可判断出,只有第一条会走索引。
版权声明
非特殊说明,本文由Zender原创或收集发布,欢迎转载。
上一篇:10,使用CAS和AQS实现自定义锁 下一篇:2、MySQL explain
相关文章



作者文章
- MyBatisCodeHelper-Pro3.3.6+2321破解 2年前 (2024-10-17)
- 网站迁移公告 2年前 (2024-10-10)
- Java项目防止SQL注入4总方式 3年前 (2023-09-06)
- JAVA开发小技巧--读取文件魔数来识别文件类型 3年前 (2023-08-24)
- 分类树菜单优化 3年前 (2023-08-22)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。